在我们使用了任何支持CLR的语言来创建了源代码文件之 后,无论使用什么编译器,编译出的文件都是一个托管模块(managed module),这个托管模块可以在CLR上运行。所以,我们把这种文件称为托管可执行文件(Managed Executable File)。关于通用PE文件的格式已经在笔记三中间记录了,这里只记录一些托管文件自身比较有特色的部分。
二.托管执行文件的重要组成部分
1.CLR Header
我们知道,在PE头中,包含一个数据目录表(Data Directory Table),这个表的第15项就是一个包含了CLR头的RVA和大小,可以通过它找到CLR Header。简单记录一下CLR Header中的几个主要的字段:
(1)Flags
这是一个二进制的标记,其可选值包括:
A. COMIMAGE_FLAGS_ILONLY (0x00000001) 文件中只包含纯的IL代码,未嵌入任何Native Code(除了Dos Stub,这个stub会被所有能够识别CLR的系统忽略掉)。
B. COMIMAGE_FLAGS_32BITREQUIRED (0x00000002) 文件只能被加载到32位的进程空间中。
C. COMIMAGE_FLAGS_STRONGNAMESIGNED (0x00000008) 文件受到强名称签名的保护
(2) EntryPointToken
这是一个指明了此PE文件入口点的元数据标志符(MeteData Identifier), 它 指向一个方法定义或者文件引用,而指向文件引用的唯一可能是:一个多模块程序集的入口点不在其主模块中,那么主模块里的入口点标记指向包含入口点的模块文 件。入口点只能出现在可执行文件里,如果你的代码里不包含入口点,IL汇编器会拒绝为你编译EXE文件。但对于非可执行文件,却分为两种情况:如果程序是 一个纯的托管程序,则不需要入口点;如果程序中即包含IL代码又包含机器码(由MC++编译器和链接器生成),则必须把DLLMain()作为入口点函 数,它要对程序集里的非托管代码进行一些必要的初始化操作。
(3) VTableFixups
要理解这个字段,首先要理解v-table的概念。这是我摘了一个老外的描述,应该很精确,“ Certain languages, which choose not to follow the common type system runtime model, may have virtual functions which need to be represented in a v-table. These v-tables are laid out by the compiler, not by the runtime. Finding the correct v-table slot and calling indirectly through the value held in that slot is also done by the compiler ”。 v-table是为虚方法调用服务的,而 VTableFixups包含了一组v-table的地址和大小。
根据笔者当前的认识,v-table只有在此托管文件 需要和 非托管环境交互的时候才有用(比如这个托管代码要被一个非托管环境调用),在纯的托管环境下可能是没用的。当然,大家都知道C#作为典型的OO语言,也有虚函数的概念,但它的虚函数实现机制和C++中的v-table的实现方式有什么不同,我暂时还不清楚。
2.文本段(.Text section)
整个CLR Header是放置在一个文本段中的。这是一个只读的段,包含了元数据表、IL代码、引入表等,整个结构如下图所示:

这个段里的各个部分并非同时生成的,上图用带序号的方框来提示这一点,序号低的先生成。
3.资源
在托管文件中可以嵌入两种不同类型的资源:非托管的平台相关的资源,或者托管资源。这两种资源存储在PE文件的不同section里(其中托管资源已经在上面的文本段内出现过了,不是吗?),其中非托管资源被放在一个单独的.rsrc段里,而托管资源放在文本段里。
需要注意的是,IL汇编器在每个托管可执行文件中只能嵌入一个资源文件(.RES)。IL反汇编器会定位到这个section,然后把section中的所有内容作为一个.RES文件释放出来。
三.元数据的结构
使用过.net的Reflection功能的人对元数据可能多少都有点概念,它是对整个托管模块的逻辑结构的完整描述,包含了所有在模块中声明和引用的元 素。从结构上来说,所有元数据类似于一个关系数据库,里面的数据体现为一组交叉引用的表(而不是树或者什么其他数据结构),并且任何数据都只有一份(其他 用到这个数据的位置都将包含一个指向此数据的引用)。从用途上来说,这些表分为三类:定义表(definition table)、引用表(reference table)和清单表(manifest table)。
整个元数据是一个二进制的数据块,你只能通过工具来查看已生成程序集的元数据信息,如ildasm.exe(你可以在“视图”菜单里找到关于元数据信息显示的命令)。
(1)元数据结构概览
下面贴出来的显示信息,是我用ildasm.exe统计了自己写的一个很小的Demo程序中的元数据信息,先放在这里,可以和后面提到的内容相互参考:
 CLR meta-data size :
1260
---------这些是元数据中的table stream----------------- Module -
1
(
10
bytes) TypeDef -
3
(
42
bytes)
0
interfaces
,
0
explicit layout TypeRef -
8
(
48
bytes) MethodDef -
8
(
112
bytes)
0
abstract
,
0
native
,
4
bodies FieldDef -
1
(
6
bytes)
0
constant MemberRef -
5
(
30
bytes) ParamDef -
9
(
54
bytes) CustomAttribute-
4
(
24
bytes) StandAloneSig -
1
(
2
bytes) Assembly -
1
(
22
bytes) AssemblyRef -
1
(
20
bytes) -----------table stream end-------------------------- -----------这些是元数据中的Heap stream------------------- Strings -
385
bytes Blobs -
108
bytes // UserStrings -
200
bytes Guids -
16
bytes -----------heap stream end--------------------------- Uncategorized -
181
bytes
CLR meta-data size :
1260
---------这些是元数据中的table stream----------------- Module -
1
(
10
bytes) TypeDef -
3
(
42
bytes)
0
interfaces
,
0
explicit layout TypeRef -
8
(
48
bytes) MethodDef -
8
(
112
bytes)
0
abstract
,
0
native
,
4
bodies FieldDef -
1
(
6
bytes)
0
constant MemberRef -
5
(
30
bytes) ParamDef -
9
(
54
bytes) CustomAttribute-
4
(
24
bytes) StandAloneSig -
1
(
2
bytes) Assembly -
1
(
22
bytes) AssemblyRef -
1
(
20
bytes) -----------table stream end-------------------------- -----------这些是元数据中的Heap stream------------------- Strings -
385
bytes Blobs -
108
bytes // UserStrings -
200
bytes Guids -
16
bytes -----------heap stream end--------------------------- Uncategorized -
181
bytes
可以看到,在元数据中除了上面我们提到的那些表以外,还有一些用于记录UserString,Guid的堆数据,后面会提到。
(2)元数据中的父子关系
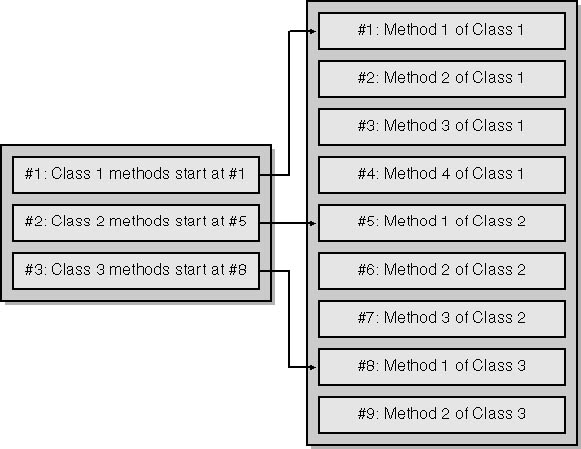
元数据中包含很多“父子关系”,如“类--方法”、“方法--参数”等等。如果你想找到和某个父数据对应的所有子数据,遍历这个子数据所在的表可是个糟糕 的选择。事实上,对于这种一对多关系,汇编器在构造元数据表的时候,并不仅仅使用数据间的引用关系,而且使用了数据的排列顺序来帮助定位。每个父数据都只 含有一个指向其第一个子数据的引用,其子数据的结尾靠下一个父数据的起始引用来定位。这就要求子数据要依照他们的父数据来排序(符合这种条件的元数据被称 为“优化的”、“压缩的”元数据,而IL汇编器一般都是生成这种元数据)。下图是书中给出的class-method父子关系的元数据表示意图:
(3)元数据结构
前面曾经提到过,元数据其实就是一个二进制的数据块,所以元数据的内部,就是一个个的named stream。这些stream又分为两种类型,除了前面提到过的Table,还有一类是以Heap的形式体现(见上文代码段中的注释)。下图是书中给出 的一个完整的元数据结构图:
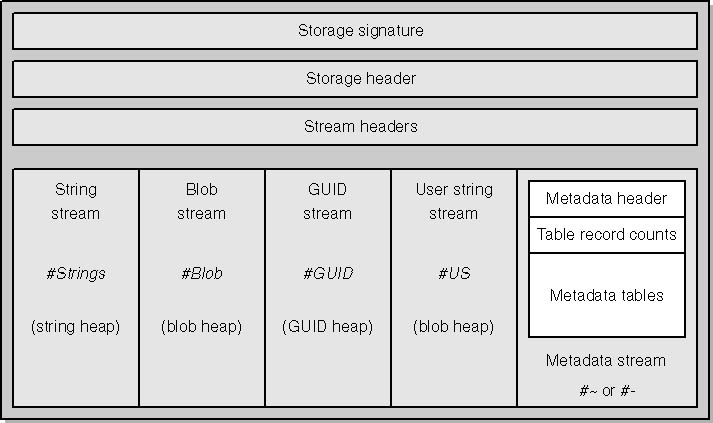
上面以#开头的就是元数据中可能出现的6个命名流,他们的用途分别是
#Strings:用来存储元数据项的名字,如类名、方法名等 //Heap Stream
#Blob: 用来存储一些内部的对象实例,如默认值什么的 //Heap Stream
#US: 用户定义的字符串常量 //Heap Stream
#GUID: 包含各种全局统一标志符 //Heap Stream
#~: “优化的”、“压缩的”元数据,里面的元数据表以优化方式存储(我们在父子关系中刚刚提到过的) //Table Stream
#-: 非优化的元数据(和#~不能共存) //Table Stream
其中(#~或#-)、#GUID、#Strings是必不可少的。
另外,元数据既然被存储在很多表里,那么CLR是如何定位一个元数据项的呢(怎么样定位到某个表的某一行)?这里,它使用了一种叫做Token的机制, 每个token占4个字节,其中高位字节表示表序号,剩余三个字节表示表内的行序号。具体这些序号被称为RID(record index),其中行序号从1开始,表序号从0开始。